Il mondo del cloud è arrivato anche nell’ambito del deep learning, uno dei settori informatici più affascinanti e promettenti degli ultimi anni. Questa tecnologia, in generale, si è affiancata all’utilizzo sulle cosiddette GPU: le Graphics Processing Unit ovvero le unità hardware di elaborazione grafica demandate ai compiti computazionali più complessi che le CPU classiche non possono eseguire con tempi e modi accettabili. Se inizialmente si usavano solo per le tradizionali schede grafiche dei PC, ad oggi le GPU sono parte integrante di applicativi di ogni genere, che vanno dalla finanza al trading passando per ricerca industriale, medicina, elaborazione avanzata di big data e così via.
Da un lato abbiamo pertanto le GPU (Graphical Processing Unit), dall’altro l’arte e la tecnica del deep learning, l’apprendimento algoritmico cosiddetto “a strati”. Quest’ultimo ha fatto la fortuna di molte applicazioni informatiche di recente generazione tra cui, per citare un esempio comune, il riconoscimento automatico di immagini o di scrittura manuale. Grazie alla tecnologia delle reti neurali (neural network), infatti, è possibile fare uso di almeno due strati di elaborazione, di cui uno primario (input layer) ed uno secondario (output layer), il tutto al fine di generare un complesso sistema di calcoli che permette di arrivare al risultato desiderato.
Si tratta di tecnologie annesse al variegato mondo dell’intelligenza artificiale e per trattarle in modo rigoroso è necessario un background non da poco. Le applicazioni reali di AI (Artificial Intelligence) sono, ad oggi, sempre più numerose, e vanno dalla creazione di deepfake (i video “falsi d’autore” con cui vari artisti ci hanno stupito in questi anni) all’uso di blockchain (il “libro mastro” con cui abilitare criptovalute, contratti digitali validi legalmente e tanto altro ancora), passando anche per l’arte della computer vision (la creazione di immagini 3D a partire da equivalenti in due dimensioni).
Deep learning e reti neurali
In questo ambito le cosiddette reti neurali sono architetture complesse su cui si basano molti dei software che utilizziamo anche solo sui nostri smartphone e che, a livello di elaborazione, possono sfruttare GPU (eventualmente da remoto). Tali tecnologie, al di là dei dettagli tecnico-matematici (complessi da spiegare senza un opportuno background matematico), sono agevoli da gestire con l’informatica tradizionale se di piccole dimensioni, come quella formalizzata per puro scopo illustrativo che possiamo vedere qui di seguito.
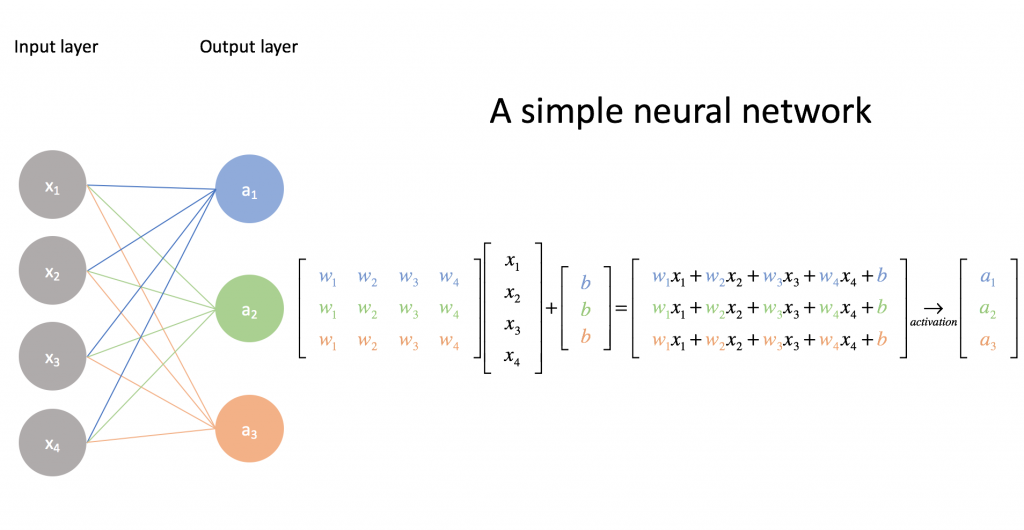
Se le dimensioni della rete aumentano, se gli strati diventano più numerosi e se il sistema è costretto per sua natura a dover gestire migliaia, se non milioni, di input differenti, l’hardware classico delle CPU tradizionali non basta più e si può valutare di “passare la palla” alle GPU.
Una GPU non è altro che un processore “specializzato” nell’eseguire le complicate operazioni che caratterizzano i rendering grafici, e per questo motivo sono molto utilizzati nell’ambito delle elaborazioni di video e immagini tridimensionali in alta definizione, ad esempio.
Perchè usare una GPU?
Il vantaggio principale di questo tipo di scelta consiste nel fatto che si scarica la CPU dell’elaboratore dall’onere di effettuare calcoli troppo complessi, delegando il compito ad un processore “dedicato” e liberando così spazio per altri task.
La differenza principale tra GPU e CPU, parlando in modo informale per non dover introdurre concetti troppo complessi, è che le GPU permettono di eseguire operazioni parallelizzate, mentre le CPU lavorano (sia pur ad altissime velocità) in modo sequenziale. Le prime, infatti, sono caratterizzate di default da componentistica dedicata alle unità logico-aritmetiche (le cosiddette ALU) e meno alla cache / controllo di quanto non avvenga per le seconde.
Questa distinzione potrebbe lasciare interdetti i meno esperti, almeno di primo acchito: l’idea che deve passare è una considerazione intuitiva sulla maggiore “velocità” di elaborazione delle GPU rispetto alle CPU. Esiste anche un video simpatico che esplica visivamente la differenza tra il sequenziamento delle CPU (la generazione di uno smile gigante disegnato un pixel per volta) ed il parallelismo delle GPU (una rielaborazione de La Gioconda prodotta all’istante), entrambe riprodotte su un palco durante questo evento dimostrativo per nerd.
Sulla commistione tra GPU e deep learning, del resto, non c’è geek o data scientist che non abbia preso in considerazione almeno una volta nella vita l’uso di una GPU come processore ad alte prestazioni per le app di natura più varia, dalla finanza alla medicina passando per le blockchain di ogni ordine e grado.
GPU e deep learning nella pratica
Abbiamo visto che GPU e deep learning sono due mondi interconnessi tra loro, che richiedono un know-how considerevole per poter essere avviati, anche solo in fase di startup. È chiaro che, pertanto, per farne uso sia necessario il più delle volte il supporto di un tecnico o consulente esperto in materia.
Un qualsiasi progetto di intelligenza artificiale, in genere, dovrà per forza di cose appoggiarsi ad una costosa GPU: è celebre a riguardo il modello NVIDIA Quadro RTX 6000, che presenta un costo considerevole proprio in relazione alle sue potenzialità. Ci sono delle alternative, per fortuna, all’acquisto dell’hardware fisico, che ci permettono comunque di fare uso di GPU: potremmo adottare le GPU in cloud offerte da Seeweb, ad esempio. Se l’opzione dell’acquisto dell’hardware potrebbe risultare difficile o economicamente non praticabile per i più, la seconda rimane un’opzione da valutare per vari motivi. Questo, ad esempio, perchè:
- con una GPU in cloud possiamo sfruttare le risorse comodamente da remoto, senza aver bisogno di installare e mantenere la GPU stessa in loco;
- avremo a disposizione il supporto tecnico degli esperti di Seeweb, sempre da remoto;
non avremo necessità di configurare il sistema, visto che è già pronto all’uso e supporta le più svariate tecnologie usate in questi ambiti (cito, ad esempio, la famosa libreria TensorFlow).
Caratteristiche tecniche del servizio di Seeweb
Le prestazioni di questo genere di servizi vengono erogate sulla base di parametri, alcuni dei quali possono essere di interesse a seconda del tipo di app di cui dovremo occuparci. Esse vengono universalmente misurate sfruttando l’unità di misura dei FLOPS, che esprime il numero di operazioni in virgola mobile che la GPU è in grado di effettuare in un secondo.
In formula avremo che tale numero è determinato da un triplice prodotto:
FLOPS = numero core X frequenza di clock X FLOP(s) per ciclo
per quanto poi, per una questione di ordini di grandezza, nel caso in questione parleremo più propriamente di TERAFLOPS, ovvero mille miliardi di FLOPS / floating operation al secondo. Più ce ne sono, ovviamente, più fluida e veloce sarà l’elaborazione dei calcoli in questione.
Seeweb mette a disposizione con il suo piano cloud GPU 24 GB di memoria dedicata GPU, in grado di funzionare a 16.3 TFLOPS al costo di 0,56€ / ora (tariffa per ora di utilizzo), con in più:
- 4,608 core CUDA (Compute Unified Device Architecture), che rappresentano le unità di calcolo fondamentali del grado di parallelismo dell’hardware, le quali sono in genere indicative della potenza computazionale in gioco;
- 576 core tensor, che giocano un ruolo fondamentale nella migliorata precisione dei calcoli effettuati;
- 72 core ray-tracing, che tipicamente intervengono a livello di elaborazione delle immagini, gestendo in modo ottimale riflessi e fotorealismo delle immagini e dei video riprodotti.
Per ulteriori informazioni potete consultare la scheda tecnica del servizio e rivolgervi all’assistenza commerciale Seeweb.


